
Yu-Ding Lu
Graduate student
ylu52 [at] ucmerced.edu
About Me
I am a second-year Graduate student in EECS at UC Merced under the advisement of Prof. Ming-Hsuan Yang. Before coming to UC Merced in 2018, I've had 3 years research experience in Machine Learning. In the past, I worked on audio signal and speech signal problems. Now I start working on audio-visual and Generative model.
My research interests include Audio-Visaul, Generative model, Speech Enhancement, Machine Learning and Speaker Verification. Here is my CV.
News
- 12/2019: One paper is accepted to IJCV
- 04/2019: One paper is accepted to NeurIPS 2019
- 05/2019: Start my research internship at FXPAL, Palo Alto, California
- 04/2019: One paper is accepted to ICIP 2019
- 08/2018: Start my Graduate program at UC Merced, California
Publications
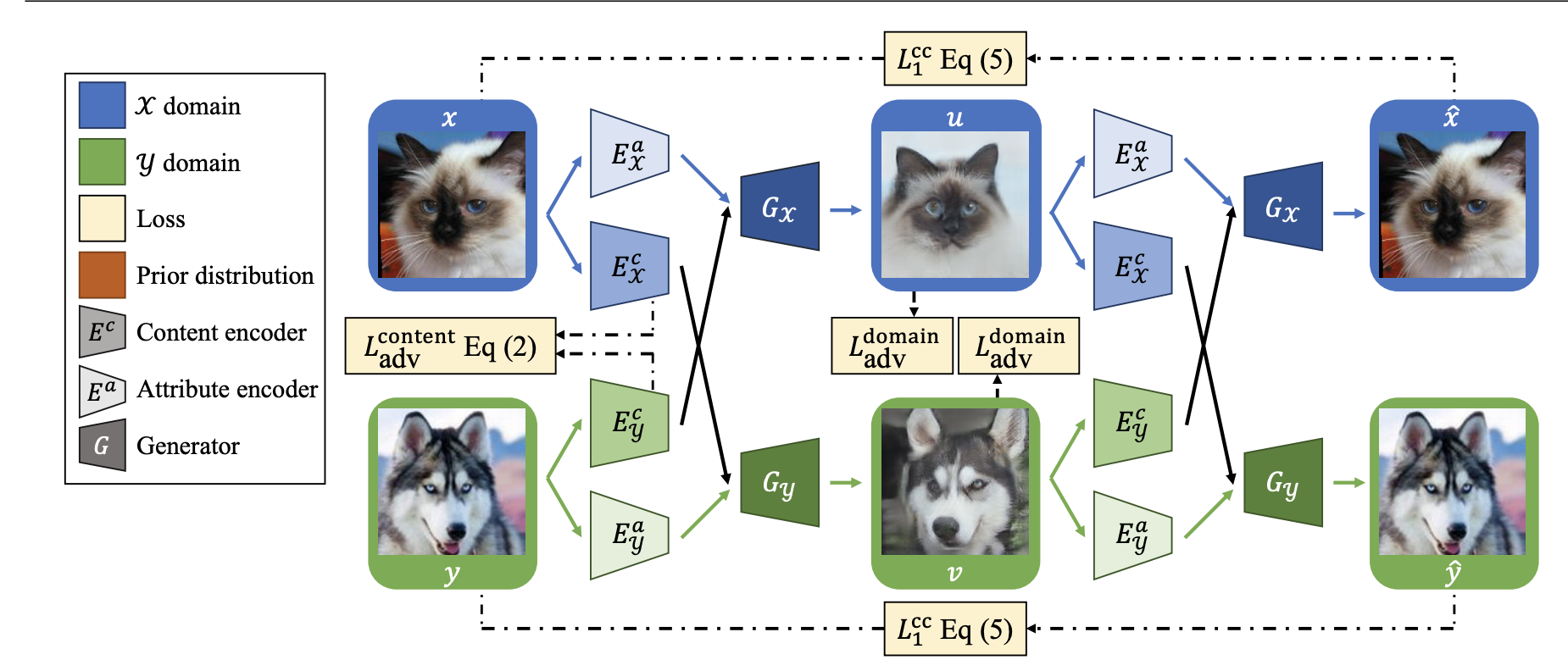
DRIT++: Diverse Image-to-Image Translation via Disentangled Representations
International Journal of Computer Vision (IJCV), 2019
Image to image translation
Generative model
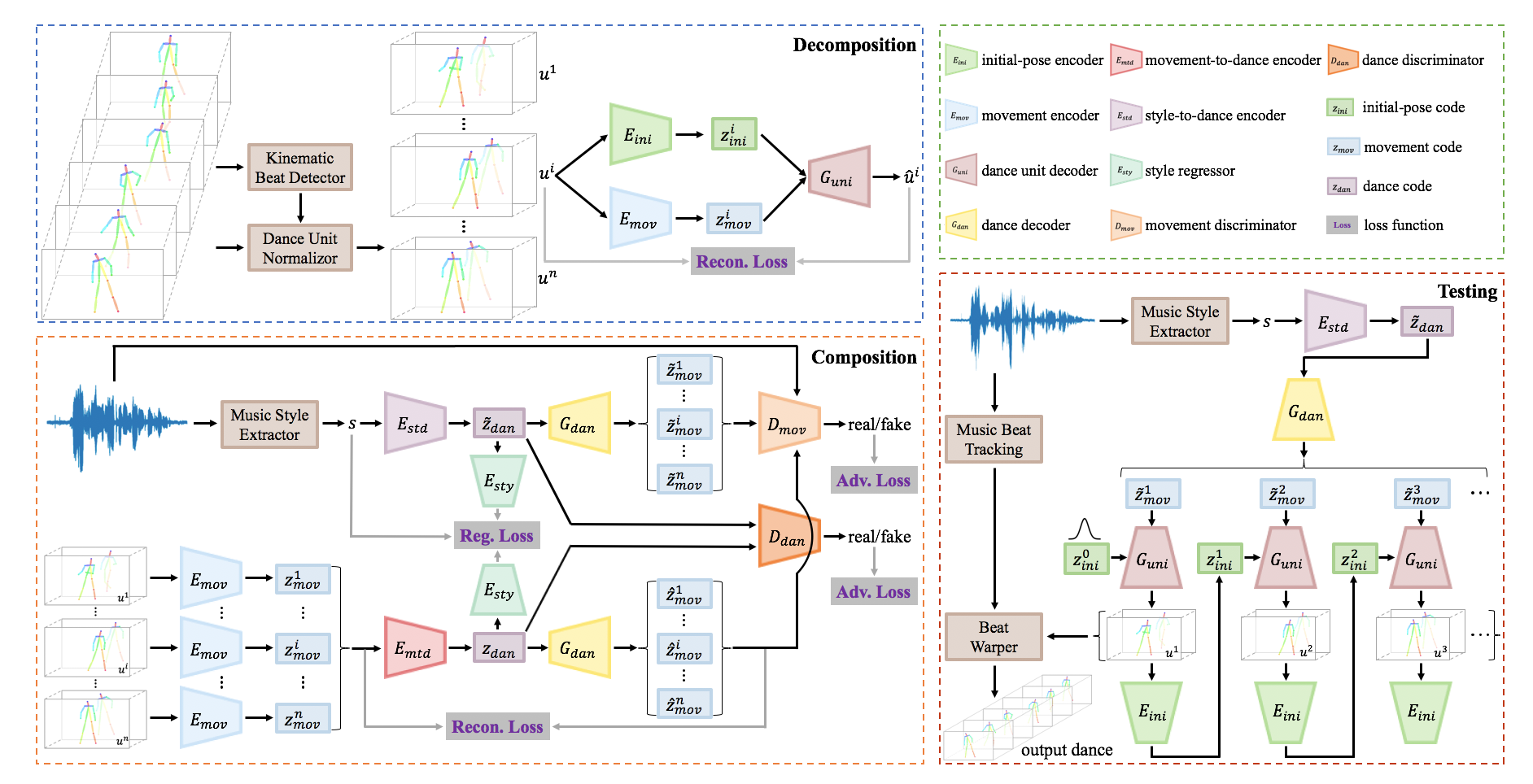
Dance to Music
Neural Information Processing Systems (NeurIPS), 2019
Audio-Visual
Generative model
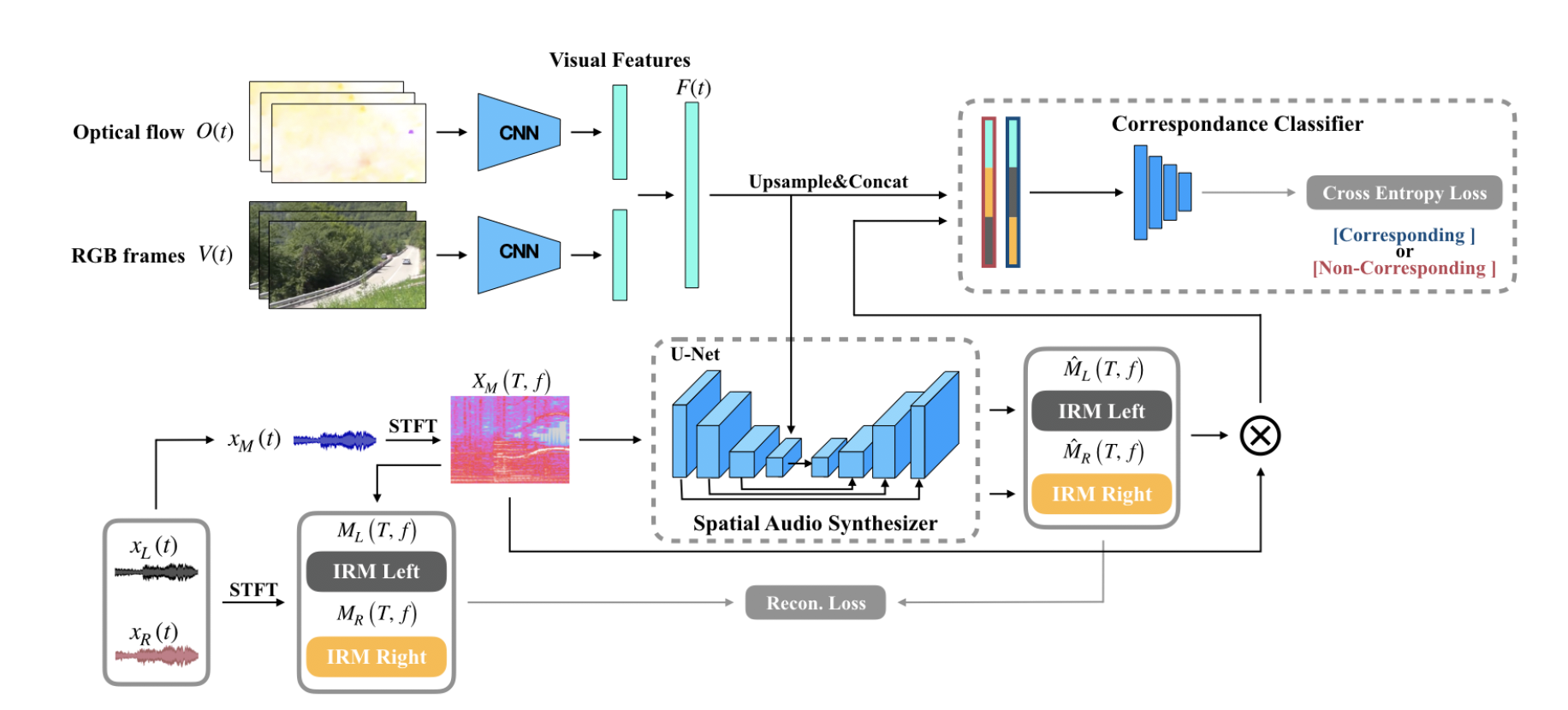

A novel LSTM-based speech preprocessor for speaker diarization in realistic mismatch conditions
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018
Speech Enhancement
Speaker Diarization
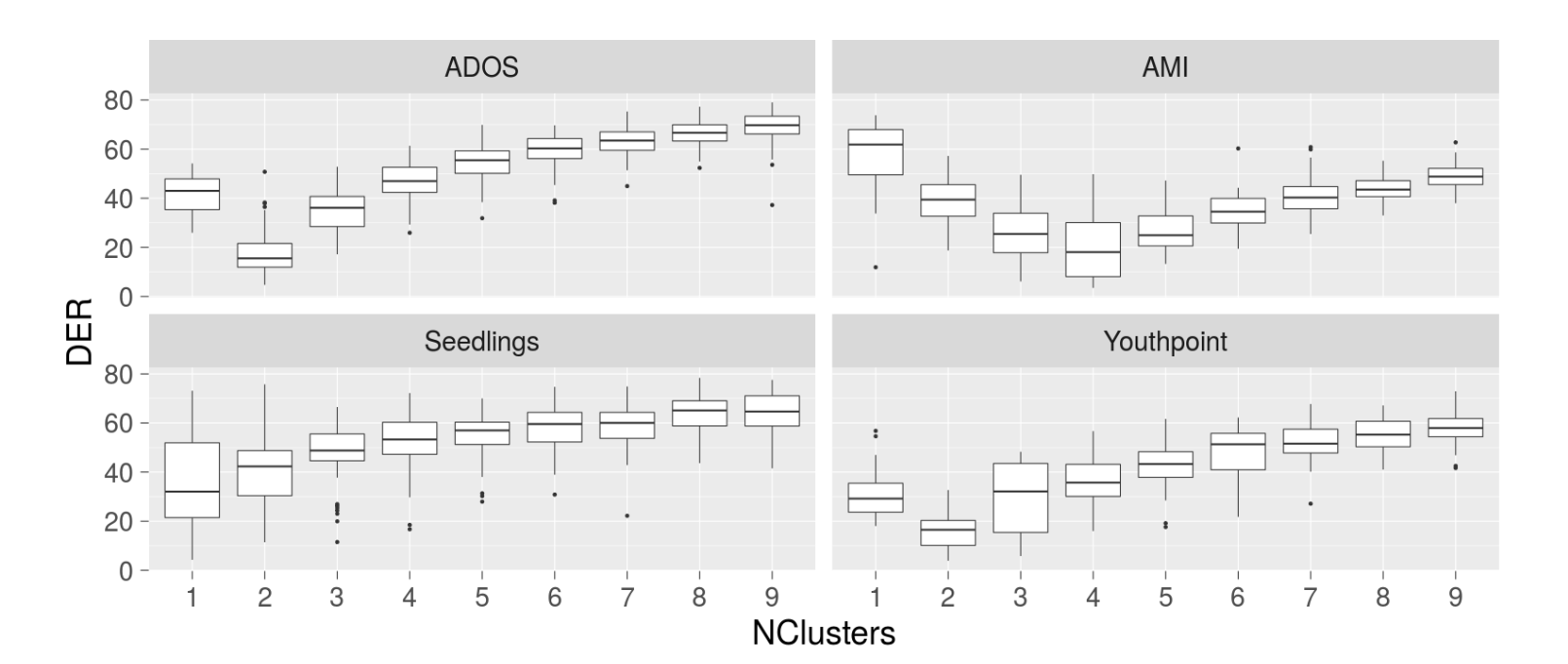
Enhancement and analysis of conversational speech: JSALT 2017
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018
Speech Enhancement
Speaker Diarization
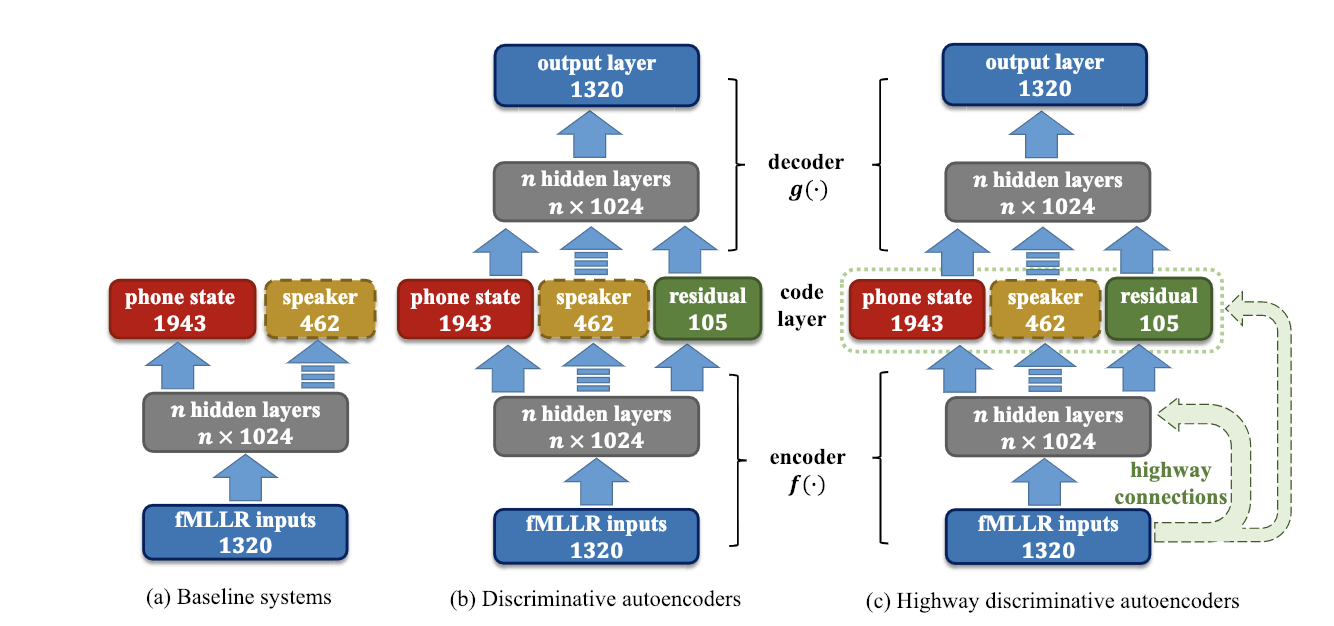
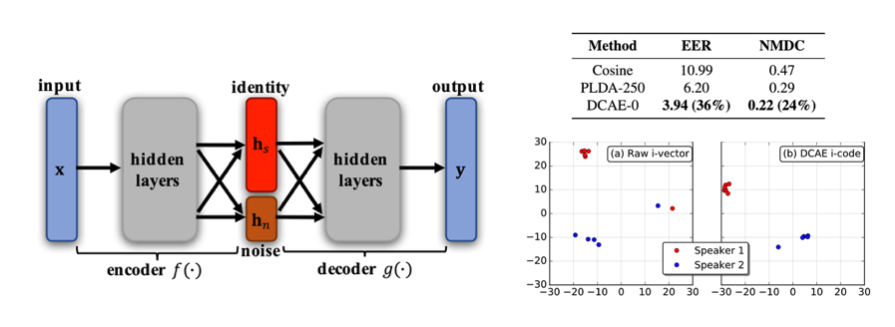
Discriminative autoencoders for speaker verification
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017
Speaker Verification
Expericence

Research Intern in FXPAL, Palo Alto, California, USA
Mar 2019 - Aug. 2019

Graduate Student in EECS, University of California, Merced, USA
Sep. 2018 - present

AI & DSP Engineer in Intelligo Technology Inc., Hsinchu, Taiwan
Dec. 2017 - Jul. 2018

Short-Term Scholar in JSALT 2017, Carnegie Mellon University, PA, USA
Jun. 2017 - Aug. 2017

RA in Biology & Audio Signal Processing Lab, Academia Sinica, Taipei, Taiwan
Mar. 2016 - Dec. 2017

B.S. in Electrical and Computer Engineering, National Chiao Tung University, Hsinchu, Taiwan
Sep. 2010 - Jun. 2014